
A recent post on Pharyngula about current debates on the evolution of gene regulatory networks in embryo development motivated me write down some thoughts about the current status of network thinking in biology. Networks are one of the latest hot items in molecular biology, but at this point, in my opinion, their significance to our current understanding is hugely overrated. More and more papers are showing up with 'network' in their titles, but most of the time, the word is uninformative about the content in the article, or just a fancy way of renaming what biologists have been doing for years - mapping the interactions between proteins, DNA, and small molecules.
What has network thinking actually done for biology? Very little except generate confusion and bad paper titles. At most, the idea of a network is used as a helpful metaphor. Metaphors can be useful in science, but if networks are to really make a big impact on our understanding of molecular biology, we need to move beyond vague metaphors and into a rigorous set of concepts that actually make a difference in how we think about biological problems.
Here's one way of looking at the situation: A recent review article by Alberto Barabasi begins by succinctly summarizing what nearly all molecular biologists would agree is a major goal:
"A key aim of postgenomic biomedical research is to systematically catalogue all molecules and their interactions within a living cell. There is a clear need to understand how these molecules and the interactions between them determine the function of this enormously complex machinery, both in isolation and when surrounded by other cells."
For at least one model organism, brewer's yeast, we're getting pretty damn close to coming up with a complete inventory of the identity, interactions, and functions of all the proteins in a cell. We know in great detail what goes on inside a yeast cell, and within 10 years, there won't be much left to discover in terms of the basic molecular biology that people have been working out for 50 years. Genomics has really accelerated this process. So the question arises, how do we make sense of all this?
This is where we hope networks will come in. As an analogy, think about a computer - you can know all about how transistors function, or how processors and buses and memory work in detail - in the case of yeast, it is like we have one particular logic board really figured out. But really, all that information only gets you so far if you don't understand things at a higher level of abstraction - if you don't understand the processor instruction set, or memory addressing, or network communication protocols.
Going back to Barabasi's review, we read further that:
"Rapid advances in network biology indicate that cellular networks are governed by universal laws and offer a new conceptual framework that could potentially revolutionize our view of biology and disease pathologies in the twenty-first century."
If only that were true. We certainly have seen advances made by people who study general properties of networks in abstract terms (Barabasi is one of those people), but I have frankly found very little to suggest that the 'universal laws' emerging from this work have deeply enhanced our understanding or predictive ability. For example, we know that many networks are 'scale free' - meaning that most network components have few connections, while a few 'hubs' have many connections. (The distribution of connections is exponential, which is what is meant we we say scale free networks follow a power law.) Why do we care whether a network is scale-free? The answer is that such networks more resistant to disruption; so scale-free biological networks are reasonably robust to mutation. After decades of genetic knock out experiments, we knew that fact already though, and while it's nice to know the source of this robustness, the utility of the scale-free concept seems to end there.
Compare this with the discoveries of the 50's and 60's - the Central Dogma: the idea that DNA makes RNA makes protein, or Jacob and Monod's model of gene regulation, which changed the way everyone in molecular biology thought about their work. These concepts set down the foundation for almost everything that happened in the next 50 years, culminating in the genome sequencing projects of the last decade. These genome sequencing projects are in some ways the ultimate validation of the importance of the Central Dogma.
I haven't come across any use of network concepts in biology that promise to be as significant. Basically, I think we don't even know how to start thinking about the next level of abstraction. Some people have made the excellent point that we shouldn't expect that level of abstraction to be closely analogous to what we see in human-designed circuits or computers, because evolution is likely to have hit upon very, very different solutions. That sounds like a tantalizing challenge.
What people have been doing instead is to just keep doing what we've been doing for 50 years, albeit with fancy genomic tools. We're still filling in details and mapping the interactions in the cell. But most of us deeply believe that there is another level of explanation - more than just having the most detailed map we can get. Sure, we can plug all those details into a computer and call it a model, but I'm not sure we'll understand much more as we do that.
So really, I think we're still waiting for networks to have a serious impact on the way we think about biology.
Wednesday, May 31, 2006
Wednesday, May 24, 2006
Check out the latest Tangled Bank
The latest issue of Tangled Bank is on Science and Politics. For readers who don't know what that is, check it out - it's sort of a weekly roundup of science blogs. I always find great stuff there.
Friday, May 19, 2006
New ideas about human-chimp speciation - the power of comparative genomics
There is a fascinating paper up on the journal Nature's website. (View the abstract here; you need a subscription for the whole paper. The NY Times has a nice piece about it here.) This paper is making the rounds on the blogosphere as well. (Most readers here probably know where to look, but for more info, the blogs I follow are on Science Blogs; the Panda's Thumb [the link's on the sidebar] is another one I read.)
I'll try to cover this paper in three parts:
1. I'll talk about the basic ideas and conclusions in the paper,
2. I'll go over some of the technical details in more depth, so we can see how this group did their analysis,
3. Finally, I'll talk about what I think this does and doesn't imply about evolution - Intelligent Design groups seem ready to jump all over every high-profile paper touching on evolution with one convoluted misinterpretation after another, so we need to deal with potential ways to misread this paper.
So, part one - what this paper is all about:
A group at the Broad Institute (which is part of both MIT and Harvard) has generated about 87 million bases of new gorilla genome sequence; this new sequence data has enabled them to line up large sections of great ape genomes and make an extremely detailed inventory of the DNA base differences among them. They conclude that these results suggest that human and chimp speciation was more complex than previously appreciated, and that there might have been some cross-breeding between the two lineages for some time after they diverged. (And no, this doesn't suggest that humans were having sex with chimps 5 million years ago - there were no humans and chimps then; there were sets of closely related species that might have interbred.)
What I find most exciting about this paper is its application of the power of comparative genomics to primates. Researchers have been comparing the genomes of different yeast species (we have dozens of yeast genomes now), different fly species, etc. and in the process we have learned a lot about both evolution and the basic biology of the cell. Over the last ten years, scientists have developed some powerful computational and statistical tools for doing this kind of analysis; now, we finally have enough primate genome sequence to really start applying these tools to the species we are most interested in - humans!
How do you compare genomes? Even before any genome sequences were available, people were saying that we are "98% chimpanzee." But this figure came from comparing the sequence of a limited number of genes; the catch is that different genes give different answers because genes can evolve at different rates. (In fact, different regions of a gene can evolve at different rate - sections of the gene crucial for a specific function tend to exhibit very few changes, while other regions can evolve fairly rapidly.) Now we can attempt to line up extensive regions of the genome, side by side, and count the number of differences in each region.
Because chimpanzees have their genetic material arranged somewhat differently (for example, some genes which are on chromosome 21 in humans are on chromosome 22 in chimps; you can also have extensive rearrangements within chromosomes), you can't just line up the entire genome from each species and compare them base by base. You have to choose regions that you can line up - regions that haven't undergone extensive rearrangements. In addition, it is helpful to have several species lined up together, to help resolve uncertainties about what kinds of changes took place. Thus, in order to look in detail at human-chimp differences, it is helpful to include genome sequence from gorillas, orangutans, and the much more genetically distant macaques.
In the current paper, the authors were able to line up thousands of regions from chimp, human, gorilla, macaque, and sometimes orangutan genomes, adding up to over thirty million DNA bases that they could directly compare among these species. Previous studies of great apes, according to the paper, covered only about 25 thousand bases.
Once these sequences were lined up, the authors basically counted up the number of bases where the sequences differ (after applying certain filters to eliminate sequence that could confound the analysis - for example, you have to pull out 'hypermutable' regions where the mutation rate is too high to make a valid comparison). The authors could divide the differences into categories - for example, you can have places where:
- the human genome differs from the other four genomes
- the chimp genome differs from the other four genomes
- humans and chimps are the same, but different from the other three
- humans and gorillas are the same, but different from the other three
- chimps and gorillas are the same, but different from the other three
etc...
These researchers found that the divergence (basically how many differences are in a given region) between the human and chimp genomes varies greatly across the genome, but if you take the average for any given chromosome, the divergence for that chromosome is fairly close to the average for the whole genome... but there is a big exception - the X chromosome, which showed a much lower divergence (circled in red in the figure below, from Patterson, et al. - the y-axis is relative divergence, with 1 being the genome average). In other words, human and chimp X-chromosomes are much more similar to each other than expected if the lineages leading to humans and chimps split off from each other 6-7 million years ago.
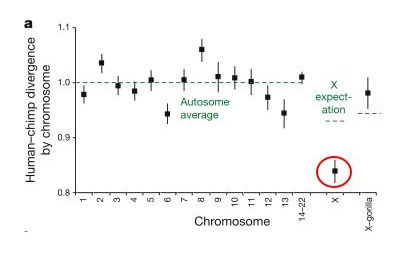
This is the most surprising finding of the study, and it is what leads the authors to suggest that interbreeding occurred between the chimp and human lineages for some time after initially diverging from each other. They suggest that there was an initial split 6-7 million years ago, roughly in line with the fossil record, but that later (less that 6.3 million years ago) there was hybridization between the two lineages resulting in some gene exchange. This paper is still new, so reactions to this scenario are just starting to trickle in, but this hypothesis is the most controversial part of the paper.
It's important to note what is not controversial though: the genomic analysis is fairly standard. The authors have used well-established statistical and computational tools to compare these genomes; the high similarity between human and chimp X chromosomes is real. These genetic analysis techniques are solid, even though some old-school anthropologists and paleontologists still resist them. The challenge now is to decide what this low X divergence is saying about how chimp-human speciation occurred, and that is where the most controversy about this paper will be.
And this is basically what scientists were saying in the NY Times article:
"David Page, a human geneticist at the Whitehead Institute in Cambridge, said the design of the new analysis was "really beautiful, with all the pieces of the puzzle laid out." Whether the hybridization will turn out to be the right solution to the puzzle remains to be seen, "but for the moment I can't think of a better explanation," he said."
In the next post, I'll go into some more technical detail about how these authors did their analysis, as an example of how useful it is to be able to compare multiple genomes.
I'll try to cover this paper in three parts:
1. I'll talk about the basic ideas and conclusions in the paper,
2. I'll go over some of the technical details in more depth, so we can see how this group did their analysis,
3. Finally, I'll talk about what I think this does and doesn't imply about evolution - Intelligent Design groups seem ready to jump all over every high-profile paper touching on evolution with one convoluted misinterpretation after another, so we need to deal with potential ways to misread this paper.
So, part one - what this paper is all about:
A group at the Broad Institute (which is part of both MIT and Harvard) has generated about 87 million bases of new gorilla genome sequence; this new sequence data has enabled them to line up large sections of great ape genomes and make an extremely detailed inventory of the DNA base differences among them. They conclude that these results suggest that human and chimp speciation was more complex than previously appreciated, and that there might have been some cross-breeding between the two lineages for some time after they diverged. (And no, this doesn't suggest that humans were having sex with chimps 5 million years ago - there were no humans and chimps then; there were sets of closely related species that might have interbred.)
What I find most exciting about this paper is its application of the power of comparative genomics to primates. Researchers have been comparing the genomes of different yeast species (we have dozens of yeast genomes now), different fly species, etc. and in the process we have learned a lot about both evolution and the basic biology of the cell. Over the last ten years, scientists have developed some powerful computational and statistical tools for doing this kind of analysis; now, we finally have enough primate genome sequence to really start applying these tools to the species we are most interested in - humans!
How do you compare genomes? Even before any genome sequences were available, people were saying that we are "98% chimpanzee." But this figure came from comparing the sequence of a limited number of genes; the catch is that different genes give different answers because genes can evolve at different rates. (In fact, different regions of a gene can evolve at different rate - sections of the gene crucial for a specific function tend to exhibit very few changes, while other regions can evolve fairly rapidly.) Now we can attempt to line up extensive regions of the genome, side by side, and count the number of differences in each region.
Because chimpanzees have their genetic material arranged somewhat differently (for example, some genes which are on chromosome 21 in humans are on chromosome 22 in chimps; you can also have extensive rearrangements within chromosomes), you can't just line up the entire genome from each species and compare them base by base. You have to choose regions that you can line up - regions that haven't undergone extensive rearrangements. In addition, it is helpful to have several species lined up together, to help resolve uncertainties about what kinds of changes took place. Thus, in order to look in detail at human-chimp differences, it is helpful to include genome sequence from gorillas, orangutans, and the much more genetically distant macaques.
In the current paper, the authors were able to line up thousands of regions from chimp, human, gorilla, macaque, and sometimes orangutan genomes, adding up to over thirty million DNA bases that they could directly compare among these species. Previous studies of great apes, according to the paper, covered only about 25 thousand bases.
Once these sequences were lined up, the authors basically counted up the number of bases where the sequences differ (after applying certain filters to eliminate sequence that could confound the analysis - for example, you have to pull out 'hypermutable' regions where the mutation rate is too high to make a valid comparison). The authors could divide the differences into categories - for example, you can have places where:
- the human genome differs from the other four genomes
- the chimp genome differs from the other four genomes
- humans and chimps are the same, but different from the other three
- humans and gorillas are the same, but different from the other three
- chimps and gorillas are the same, but different from the other three
etc...
These researchers found that the divergence (basically how many differences are in a given region) between the human and chimp genomes varies greatly across the genome, but if you take the average for any given chromosome, the divergence for that chromosome is fairly close to the average for the whole genome... but there is a big exception - the X chromosome, which showed a much lower divergence (circled in red in the figure below, from Patterson, et al. - the y-axis is relative divergence, with 1 being the genome average). In other words, human and chimp X-chromosomes are much more similar to each other than expected if the lineages leading to humans and chimps split off from each other 6-7 million years ago.
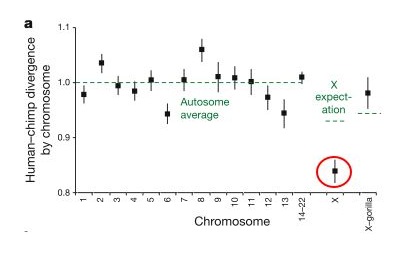
This is the most surprising finding of the study, and it is what leads the authors to suggest that interbreeding occurred between the chimp and human lineages for some time after initially diverging from each other. They suggest that there was an initial split 6-7 million years ago, roughly in line with the fossil record, but that later (less that 6.3 million years ago) there was hybridization between the two lineages resulting in some gene exchange. This paper is still new, so reactions to this scenario are just starting to trickle in, but this hypothesis is the most controversial part of the paper.
It's important to note what is not controversial though: the genomic analysis is fairly standard. The authors have used well-established statistical and computational tools to compare these genomes; the high similarity between human and chimp X chromosomes is real. These genetic analysis techniques are solid, even though some old-school anthropologists and paleontologists still resist them. The challenge now is to decide what this low X divergence is saying about how chimp-human speciation occurred, and that is where the most controversy about this paper will be.
And this is basically what scientists were saying in the NY Times article:
"David Page, a human geneticist at the Whitehead Institute in Cambridge, said the design of the new analysis was "really beautiful, with all the pieces of the puzzle laid out." Whether the hybridization will turn out to be the right solution to the puzzle remains to be seen, "but for the moment I can't think of a better explanation," he said."
In the next post, I'll go into some more technical detail about how these authors did their analysis, as an example of how useful it is to be able to compare multiple genomes.
Monday, May 01, 2006
NY Times distorts peer review
The NY Times has an odd article called "For Science's Gatekeepers, a Credibility Gap". For starters, this article (by a physician named Lawrence Altman) is not that well written. There is very little serious reporting in the article; instead, it's filled with general sentences like this one:
"But many authors have still withheld information for fear that journals would pull their papers for an infraction. Increasingly, journals and authors' institutions also send out news releases ahead of time about a peer-reviewed discovery so that reports from news organizations coincide with a journal's date of issue."
Normally, at this point, a genuine reporter would then cite sources who were interviewed for the article, or go into more detail. Instead, this piece just continues on with more of the same:
"A barrage of news reports can follow. But often the news release is sent without the full paper, so reports may be based only on the spin created by a journal or an institution."
Again, no sources or specific examples are cited.
Besides the fact that this article has no serious reporting, it completely mischaracterizes the peer-review system that is the standard for publishing serious research. Here are some gems from the article:
"The publication process is complex. Many factors can allow error, even fraud, to slip through. They include economic pressures for journals to avoid investigating suspected errors; the desire to avoid displeasing the authors and the experts who review manuscripts; and the fear that angry scientists will withhold the manuscripts that are the lifeline of the journals, putting them out of business. By promoting the sanctity of peer review and using it to justify a number of their actions in recent years, journals have added to their enormous power."
Huh??? "They fear that angry scientists will withold the manuscripts..." I personally know prominent scientists who frequently have papers rejected by top journals; I also personally know editors of journals. The idea that editors accept fraudulent science because they are afraid of angering scientists who will never send them a manuscript again is just total crap. Rejection is a normal part of life for all scientists. Nobody gets all of their papers into Science or JAMA, and fear of authors' anger is not really a major factor in editors' decisions.
Is peer review just part of a cynical game on the part of journals to add 'to their enormous power?" This article tries to make you think so:
"The release of news about scientific and medical findings is among the most tightly managed in country. Journals control when the public learns about findings from taxpayer-supported research by setting dates when the research can be published."
This is absurd - journals are trying to exert tight control over scientific information "by setting dates when the research can be published"???? What happens in reality is this: authors submit a paper, and when it's accepted, it enters the publication pipeline and gets published on a routine timescale. Sometimes a journal will receive two closely related papers in a short period of time; the editors will try to publish both articles back to back in the same issue. In other cases, the findings of a particular study are considered unusually significant, and the manuscript will go through an accelerated publication process (after the paper makes it through peer-review). While a manuscript is under review or awaiting publication, authors frequently present their findings in seminars and conferences, which are generally open to any taxpayer or journalist who cares to attend and listen to a highly technical talk. There is no conspiracy to control what the public learns.
And then there's the paragraph that I quoted before: [I'm not sure what the logical connection is between these two sentences in this paragraph]
"But many authors have still withheld information for fear that journals would pull their papers for an infraction. Increasingly, journals and authors' institutions also send out news releases ahead of time about a peer-reviewed discovery so that reports from news organizations coincide with a journal's date of issue."
It's hard to resist the temptation to just quote bad paragraph after bad paragraph (just go read the article yourself.) It's just so odd that this was considered fit to print by the NY Times.
Here is where I think Altman really goes wrong (other than his attempt to ascribe peer-review's power to a conspiracy of power-hungry journal editors):
Peer-review isn't really set up to catch fraud. And this is not because editors are trying to avoid offending authors, or increase their power over the scientific and medical information available to the public. The real reason is this: peer-reviewers check a manuscript for flaws in reasoning and methodology (did the authors leave out any crucial experiments, was the experimental design subject to unacknowledged error, or did they misinterpret their results?), and they evaluate a paper's scientific merit (they ask, is this a significant achievement in the field?). That's basically it. If authors have falsified their data, reviewers may very well not catch it. Peer-review is still based on trust.
Is scientific fraud a growing problem? Only because the population of scientists is growing. If you have more practicing scientists, you're going to have more fraud. And fraud is caught (always by other scientists) and punished severely. Unlike in politics, business, and even law and medicine, fraud is a complete career-ender in science. Scientists guilty of serious fraud cannot get grants, they lose their academic positions, and can never publish in a reputable journal again. They can no longer be scientists. Fraud is punished more harshly in science than in almost any other profession.
Maybe the NY Times can use a little peer-review for some of their pieces.
"But many authors have still withheld information for fear that journals would pull their papers for an infraction. Increasingly, journals and authors' institutions also send out news releases ahead of time about a peer-reviewed discovery so that reports from news organizations coincide with a journal's date of issue."
Normally, at this point, a genuine reporter would then cite sources who were interviewed for the article, or go into more detail. Instead, this piece just continues on with more of the same:
"A barrage of news reports can follow. But often the news release is sent without the full paper, so reports may be based only on the spin created by a journal or an institution."
Again, no sources or specific examples are cited.
Besides the fact that this article has no serious reporting, it completely mischaracterizes the peer-review system that is the standard for publishing serious research. Here are some gems from the article:
"The publication process is complex. Many factors can allow error, even fraud, to slip through. They include economic pressures for journals to avoid investigating suspected errors; the desire to avoid displeasing the authors and the experts who review manuscripts; and the fear that angry scientists will withhold the manuscripts that are the lifeline of the journals, putting them out of business. By promoting the sanctity of peer review and using it to justify a number of their actions in recent years, journals have added to their enormous power."
Huh??? "They fear that angry scientists will withold the manuscripts..." I personally know prominent scientists who frequently have papers rejected by top journals; I also personally know editors of journals. The idea that editors accept fraudulent science because they are afraid of angering scientists who will never send them a manuscript again is just total crap. Rejection is a normal part of life for all scientists. Nobody gets all of their papers into Science or JAMA, and fear of authors' anger is not really a major factor in editors' decisions.
Is peer review just part of a cynical game on the part of journals to add 'to their enormous power?" This article tries to make you think so:
"The release of news about scientific and medical findings is among the most tightly managed in country. Journals control when the public learns about findings from taxpayer-supported research by setting dates when the research can be published."
This is absurd - journals are trying to exert tight control over scientific information "by setting dates when the research can be published"???? What happens in reality is this: authors submit a paper, and when it's accepted, it enters the publication pipeline and gets published on a routine timescale. Sometimes a journal will receive two closely related papers in a short period of time; the editors will try to publish both articles back to back in the same issue. In other cases, the findings of a particular study are considered unusually significant, and the manuscript will go through an accelerated publication process (after the paper makes it through peer-review). While a manuscript is under review or awaiting publication, authors frequently present their findings in seminars and conferences, which are generally open to any taxpayer or journalist who cares to attend and listen to a highly technical talk. There is no conspiracy to control what the public learns.
And then there's the paragraph that I quoted before: [I'm not sure what the logical connection is between these two sentences in this paragraph]
"But many authors have still withheld information for fear that journals would pull their papers for an infraction. Increasingly, journals and authors' institutions also send out news releases ahead of time about a peer-reviewed discovery so that reports from news organizations coincide with a journal's date of issue."
It's hard to resist the temptation to just quote bad paragraph after bad paragraph (just go read the article yourself.) It's just so odd that this was considered fit to print by the NY Times.
Here is where I think Altman really goes wrong (other than his attempt to ascribe peer-review's power to a conspiracy of power-hungry journal editors):
Peer-review isn't really set up to catch fraud. And this is not because editors are trying to avoid offending authors, or increase their power over the scientific and medical information available to the public. The real reason is this: peer-reviewers check a manuscript for flaws in reasoning and methodology (did the authors leave out any crucial experiments, was the experimental design subject to unacknowledged error, or did they misinterpret their results?), and they evaluate a paper's scientific merit (they ask, is this a significant achievement in the field?). That's basically it. If authors have falsified their data, reviewers may very well not catch it. Peer-review is still based on trust.
Is scientific fraud a growing problem? Only because the population of scientists is growing. If you have more practicing scientists, you're going to have more fraud. And fraud is caught (always by other scientists) and punished severely. Unlike in politics, business, and even law and medicine, fraud is a complete career-ender in science. Scientists guilty of serious fraud cannot get grants, they lose their academic positions, and can never publish in a reputable journal again. They can no longer be scientists. Fraud is punished more harshly in science than in almost any other profession.
Maybe the NY Times can use a little peer-review for some of their pieces.
Subscribe to:
Posts (Atom)


